Como utilizar Python dentro do Power BI?
Python e R são duas linguagens de programação open source amplamente utilizadas no meio da Ciência de Dados, pois conseguem lidar muito bem com grandes volumes de dados, com análises estatísticas avançadas, tais como Machine Learning e inteligência artificial. E agora imagine aliar tudo isso ao Power BI, que é excelente na parte de visualização? É um prato cheio para aumentarmos nossa bagagem de conhecimentos e as possibilidades que essas ferramentas nos trazem.
No artigo de hoje vamos explorar sobre como utilizar a linguagem Python dentro do Power BI.

Caso você queira saber mais sobre as linguagens Python e R, recomendo a leitura dos nossos artigos:
Um bom motivo para utilizarmos o Python dentro do Power BI é o facto de termos mais liberdade de criação. Digo, por mais que criemos nossos gráficos no Power BI, sempre há limitações ou então temos que recorrer e buscar no repositório das apps. Já com o Python podemos programa do jeito que quisermos. Ou seja, aumenta o nosso poder de desenvolvimento.

Algumas possibilidade de uso do Python no Power Bi:
- Para importar fontes de dados que não estão disponíveis ou não performam tão bem no PBI (web scrapping, bases não relacionais, etc);
- Para aplicar transformações de dados do Power Query
- Para incorporar Machine Learning na sua base
- Para criar elementos visuais customizados com bibliotecas Python
Contexto
Antes de tudo, precisamos entender que tanto a linguagem R quanto a linguagem Python são linguagens interpretadas e é comum utilizarmos uma IDE (um ambiente integrado de desenvolvimento) pela praticidade e maior produtividade. Uma IDE, a grosso modo, podemos dizer que é um programa, uma ferramenta de codificação que nos permite escrever, testar e depurar nossos códigos de uma maneira mais fácil. Ou seja, um software para desenvolvermos o nosso código para ciência de dados que tornam a análise de dados e o aprendizado de máquina mais fácil.
No caso do R, costumamos utilizar o RStudio, mas no caso do Python, não há ainda o Python Studio, mas sim várias IDE’s que podemos escolher, como por exemplo:
- PyCharm: https://www.jetbrains.com/pycharm/
- Visual Studio Code: https://code.visualstudio.com/
- Spyder (sua interface lembra muito o RStudio): https://www.spyder-ide.org/
- Thonny: https://thonny.org/
- Atom: https://atom.io/
- Jupyter Notebook: https://jupyter.org/
- Google Colab (uma IDE da Web que funciona em cloud e não necessita instalação nenhuma, apenas uma conta de e-mail do tipo gmail):
- https://colab.research.google.com/notebooks/intro.ipynb
- Etc
Já com relação à linguagem ser interpretada, significa que utilizamos interpretadores. Interpretadores são programas de computador que leem um código fonte de uma linguagem de programação e os convertem em código executável. O seu funcionamento pode variar de acordo com a implementação. Em muitos casos o interpretador lê linha-a-linha e converte em código objeto à medida que vai executando o programa. Linguagens interpretadas são mais dinâmicas por não precisarem escrever-compilar-testar-corrigir-compilar-testar-distribuir, e sim escrever-testar-corrigir-escrever-testar-distribuir.
Se não tivermos um interpretador da linguagem Python instalado, nós não conseguimos usar o Python no Power BI. Isso porque o Power BI não interpreta a linguagem Python e sim, ele chama o interpretador que eventualmente temos instalado no SO. Ele faz isso tanto para a linguagem Python quanto para a linguagem R. É por isso que, para esse último, instalamos primeiro o R e depois o RStudio.
No caso do Python vamos instalar o interpretador Anaconda. Este interpretador tem uma grande vantagem pois já vem com mais de 1500 pacotes instalados, inclusive os conhecidos como: Matplotlib, Seaborn, Pandas, NumPy.
Como instalar o Anaconda?
- No site Anaconda https://www.anaconda.com/
- Aceda ao friso ‘Products’ > Individual Edition

- Download para o seu sistema operacional (no meu caso será Python 3.8, 64-Bits para Windows)

- I agree > Just me > Next > escolher o diretório > Next > marcar as 2 caixinhas > Install

Quando marcamos a primeira caixinha, o instalador irá acrescentar o caminho da instalação da linguagem Python (Anaconda) nas variáveis de ambiente. Basicamente, ele vai dizer para o seu sistema operacional onde ele vai encontrar o programa.
- Next > Finish
Neste momento, já temos a linguagem Python devidamente instalada. E se quisermos verificar se resultou, podemos aceder ao Shell do interpretador da linguagem
- Botão direito em cima do menu iniciar do Windows > Run (ou executar)

- Digite ‘cmd’ > OK

- Digite ‘python’ e clique no enter

- Para sair do Shell do interpretador, bastar digitar logo depois dos >>> exit() e fechar no X
Integração entre Python e Power BI
O elemento visual Python pode ser acedido no Power BI Desktop através do friso de Visualizações.

Ao clicar no ícone, ative para habilitarmos o Python no Power BI

Vá para configurações, na engrenagem para verificarmos as opções e definições:

Em Scripts de Python, podemos ver que o Power BI já reconheceu que temos um interpretador instalado (o Anaconda).

Dessa forma, o Power BI agora consegue interpretar códigos Python. Tudo o que precisamos fazer agora é inserir os scripts no Editor de scripts Python.
Caso já tenha alguma IDE instalada, poderá configurá-la no passo 3. Mas também não é obrigatório. Saiba que podemos simplesmente digitar o script diretamente no Power BI.
Se optarmos por trabalhar com a IDE do Jupyter Notebook ou com o Google Colab, por exemplo, saiba que eles funcionam via navegador e que, portanto, não vamos conseguir configurar no passo 3 mostrado anteriormente.
Como criar um gráfico com Python dentro do Power BI?
Embora o Power BI tenha uma biblioteca abrangente de visualização, não é tão simples criar uma matriz de correlação nele. Ainda assim, o mapa de calor da matriz de correlação é um componente integral dos relatórios de análise de dados.
Nesta seção, demonstraremos como criar um mapa de calor da matriz de correlação usando a função de correlação do Python que será exibido no nosso relatório do Power BI.
- Precisamos trazer os dados para dentro do Power BI > vou trabalhar com uma base de dados para um modelo de Churn (leia mais sobre esse assunto em um outro artigo nosso: https://www.portal-gestao.com/artigos/8166-customer-churn-como-prever-e-evitar-perder-clientes.html )
- Caso seja necessário, realizar a limpeza da base de dados (processo de ETL) > Close and Apply
- Selecionar o elemento visual do Python (Ícone Py)
- O campo Valores, estará vazio > Traga as variáveis de interesse (no meu caso, vou utilizar todas as variáveis contínuas e numéricas que tenho disponíveis, tais como, idade, salário médio, saldo dos meses anteriores e atual, etc) > Este é um passo importante. Caso contrário, o Power BI não reconheceria essas variáveis como parte da visualização.
- Note que automaticamente o Power BI começa a criar o nosso dataset (Conforme colocamos as variáveis no campo Valores , o script Python é preenchido automaticamente com os códigos)

- Para criar o mapa de calor, precisamos criar uma matriz de correlação (coeficiente de Pearson) > Para isso, precisaremos importar algunas as bibliotecas > eu importei o Matplotlib e o Seaborn, que são bibliotecas de visualizações de dados
- Após finalizar o código, podemos rodá-lo através do botão ‘Executar script’
Código utilizado
# O seguinte código para criar um dataframe e remover as linhas duplicadas é sempre executado e atua como um preâmbulo para o seu script:
# dataset = pandas.DataFrame(age, previous_month_balance, previous_month_credit, previous_month_debit,
previous_month_end_balance, average_monthly_balance_prevQ, average_monthly_balance_prevQ2,
current_balance, current_month_balance, current_month_credit, current_month_debit, dependents, vintage) # dataset = dataset.drop_duplicates() # Cole ou escreva o código do script aqui: # Importar as bibliotecas matplotlib and seaborn import matplotlib.pyplot as plt import seaborn as sns # Criar a matriz de correlação com os dados do nosso dataset corr = dataset.corr() # Criar a heatmap da matriz de correlação sns.heatmap(corr, cmap="Blues") # mostrar o gráfico plt.show()
Gerando relatórios analíticos
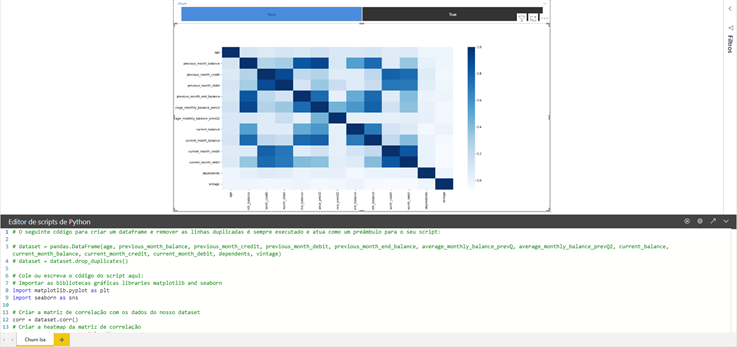
Depois de analisar o mapa de calor, podemos concluir:
Para todos os clientes,
- Idade e número de dependentes não têm correlação com as demais variáveis
- Saldo médio mensal nos últimos dois trimestres estão moderadamente correlacionados
- O saldo médio mensal no último trimestre está altamente correlacionado com o saldo do mês atual e o saldo do mês anterior
Podemos produzir este mapa de calor para clientes que ‘Churnaram’ e compará-lo com aqueles que não o fizeram. Assim, aplicamos um filtro de churn = True ou False usando as caixas azuis para observar o mapa de calor para os dois grupos de clientes separadamente.
O gráfico abaixo representa a imagem para clientes que não cancelaram. No entanto, uma história diferente emerge para esses dois tipos de clientes. Os clientes que não cancelaram possuem uma correlação muito maior entre o saldo médio mensal dos dois últimos trimestres e o saldo do mês corrente e do mês anterior.

Já para os clientes cancelados, o saldo médio mensal dos dois últimos trimestres tem correlação baixa a moderada com o saldo do mês corrente e do mês anterior.
Portanto, esta análise demonstra como podemos extrair alguns insights úteis da análise dos dados para prever o comportamento de clientes que mudam.
Notas finais
Neste artigo, aprendemos sobre a integração do Python com o Power BI. Usamos os recursos de relatório do Power BI junto com os recursos analíticos do Python para construir um relatório analítico.
Para concluir, este ambiente integrado dá mais poder às mãos de cientistas de dados e profissionais de inteligência de negócios. Eles podem capitalizar facilmente os aspetos benéficos de ambas as ferramentas. Como sempre menciono: quantas mais ferramentas sabemos utilizar, mais problemas conseguimos resolver.
Referências
https://docs.microsoft.com/pt-br/visualstudio/python/installing-python-interpreters?view=vs-2019
